一、问题
Spring + MyBatis项目中需要对SQL的执行时间做简单的监控,打印MyBatis SQL ID、SQL语句,耗时等信息。目的是找出慢SQL来优化。
使用的方案是增加MyBatis的Interceptorl拦截Executor.class类和query和update方法,统计SQL执行时间,并提取SQL ID和语句,通过logback日志组件异步写本地文件。FileBeat agent读本地日志文件并上报ES存储和查询。
遇到的问题是开启SQL监控后参数多的大SQL观察到明显性能下降,比如in子查询中的参数列表很多时(万级别)。我们场景中MyBatis关联的数据库层包括MySQL和ClickHouse。ClickHouse对应的查询包括复杂聚合统计函数,单SQL执行时间可能到秒级别。出问题场景请求多个SQL叠加执行时间累加达分钟级别。
这里的调优只考虑监控代码自身的调优,不包括慢SQL。
二、分析
现有监控代码都在MyBatis的Interceptor中。重点看这部分逻辑。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
| package com.xxx.config.mybatis;
import ... (省略)
@Slf4j
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {
MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class
}),
@Signature(type = Executor.class, method = "query", args = {
MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class
}),
@Signature(type = Executor.class, method = "update", args = {
MappedStatement.class, Object.class
})
})
public class SqlMonitorInterceptor implements Interceptor {
private static final Logger perfLogger = LoggerFactory.getLogger("PERFORMANCE_LOGGER");
private static final ObjectMapper objectMapper = new ObjectMapper();
private final MeterRegistry meterRegistry;
private static final String HOSTNAME;
private static final String HOST_IP;
private static final String APP_NAME = "xxx-app";
private static final String LOG_TYPE = "sql_performance";
private static final long SLOW_SQL_THRESHOLD_MS = 0;
static {
objectMapper.registerModule(new JavaTimeModule());
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
String hostname = "unknown";
String ip = "unknown";
try {
InetAddress localHost = InetAddress.getLocalHost();
hostname = localHost.getHostName();
ip = localHost.getHostAddress();
} catch (Exception e) {
log.warn("sql interceptor init exception: {}", e.getMessage());
}
HOSTNAME = hostname;
HOST_IP = ip;
}
@Override
public Object intercept(Invocation invocation) throws Throwable {
long start = System.nanoTime();
String finalSql = "";
try {
return invocation.proceed();
} finally {
String statId = "";
try {
MappedStatement ms = (MappedStatement) invocation.getArgs()[0];
Object parameter = invocation.getArgs().length > 1 ? invocation.getArgs()[1] : null;
BoundSql boundSql = ms.getBoundSql(parameter);
statId = ms.getId();
long end = System.nanoTime();
long durationMs = TimeUnit.NANOSECONDS.toMillis(end - start);
if (durationMs > SLOW_SQL_THRESHOLD_MS) {
finalSql = buildFinalSql(boundSql);
PerformanceLog logEntry = PerformanceLog.builder()
.logType(LOG_TYPE)
.hostname(HOSTNAME)
.hostIp(HOST_IP)
.appName(APP_NAME)
.metricKey(statId)
.metricDesc(finalSql)
.elapsedMs(durationMs)
.timestamp(Instant.now())
.build();
String json = objectMapper.writeValueAsString(logEntry);
perfLogger.info(json);
log.debug("statement: {}, finalSql: {}", ms.getId(), finalSql);
}
} catch (Exception ex) {
log.warn("[ERROR SQL Interceptor] {} | {}", statId, finalSql, ex);
}
}
}
private String buildFinalSql(BoundSql boundSql) {
String sql;
try {
sql = boundSql.getSql().replaceAll("\\s+", " ");
if (boundSql.getParameterMappings() != null) {
for (ParameterMapping pm : boundSql.getParameterMappings()) {
Object value;
String propertyName = pm.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (boundSql.getParameterObject() != null) {
Object paramObject = boundSql.getParameterObject();
if (paramObject instanceof Map) {
value = ((Map<?, ?>) paramObject).get(propertyName);
} else {
value = paramObject;
}
} else {
value = null;
}
String replacement = (value instanceof String) ? "'" + value + "'" : String.valueOf(value);
sql = sql.replaceFirst("\\?", replacement != null ? java.util.regex.Matcher.quoteReplacement(replacement) : "null");
}
}
} catch (Exception ex) {
log.warn("build final sql error: {}", ex.getMessage());
sql = boundSql.getSql();
}
return sql;
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {}
}
|
这段代码主要作用如下:
- 拦截SQL的执行类和方法
- 统计SQL执行耗时。提取SQL ID、参数、原始SQL、参数替换的SQL,按ES定义的字段格式写本地日志文件
优化过程如下:
迭代一
通过代码中打点增加日志,定位到瓶颈点在buildFinalSql中的replaceFirst正则表达式。这个函数作用是通过SQL模版和参数替换成真正执行的SQL字符串。这是在一个循环中,循环次数同ParameterMappings列表的大小,这个跟参数大小有关(in子查询中列表每个元素对应一个参数而不是整个in子查询对应一个)。正则本来就是一个性能杀手,对应几万级别参数时性能差就能理解了。
解决方法
- 把正则改写为字符串查找和替换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| private String buildFinalSql(BoundSql boundSql, String originalSql, String statId) {
long start = System.nanoTime();
String sql = originalSql;
try {
if (boundSql.getParameterMappings() != null && !boundSql.getParameterMappings().isEmpty()) {
StringBuilder sqlBuilder = new StringBuilder(originalSql);
int offset = 0;
for (ParameterMapping pm : boundSql.getParameterMappings()) {
Object value = getParameterValue(boundSql, pm);
String replacement = (value instanceof String) ? "'" + value + "'" : String.valueOf(value);
replacement = replacement != null ? replacement : "null";
int paramIndex = sqlBuilder.indexOf("?", offset);
if (paramIndex != -1) {
sqlBuilder.replace(paramIndex, paramIndex + 1, replacement);
offset = paramIndex + replacement.length();
}
}
sql = sqlBuilder.toString();
}
} catch (Exception ex) {
log.warn("build final sql error, statId: {}", statId, ex);
}
log.debug("build final sql cost: {} ms, statId: {}", TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start), statId);
return sql;
}
|
- 增加业务开关,参数太多时直接上报原始SQL不做参数替换(参数可以单独写另外日志字段上报,这个暂时没处理)。通过调整参数大小,buildFinalSql性能基本可以做到可控,大不了不替换,都直接上报原始SQL。
迭代二
继续观察打点信息,发现新的瓶颈点ms.getBoundSql(parameter)。
1
2
3
| Object parameter = invocation.getArgs().length > 1 ? invocation.getArgs()[1] : null;
BoundSql boundSql = ms.getBoundSql(parameter);
|
通过AI了解了一下,这个跟Interceptor拦截的类有关。我们拦截的是Executor.class, 推荐用StatementHandler.class。
理解了一下,这个跟SQL执行的顺序有关。JDBC先准备PreparedStatement再执行。在PreparedStatement阶段,已经对SQL模版进行了参数替换。这里拦截就可以直接拿到编译后的statement。
如果在SQL执行阶段拦截,会重新触发SQL编译,除非通过反射拿到Prepared阶段的对象。这就是getBoundSql耗时的原因。
解决方法也很简单,通过AI把原来的代码改写一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| @Intercepts({
// 拦截 StatementHandler 的 prepare 方法是获取 BoundSql 的最佳时机
@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class}),
// 如果需要更精准的耗时统计,也可以拦截 update 或 query
@Signature(type = StatementHandler.class, method = "update", args = {java.sql.Statement.class}),
@Signature(type = StatementHandler.class, method = "query", args = {java.sql.Statement.class, org.apache.ibatis.session.ResultHandler.class})
})
public class SqlMonitorInterceptor implements Interceptor {
...
@Override
public Object intercept(Invocation invocation) throws Throwable {
long start = System.nanoTime();
// 1. 获取 StatementHandler 和 MetaObject
StatementHandler handler = (StatementHandler) invocation.getTarget();
MetaObject metaObject = SystemMetaObject.forObject(handler);
// 2. 直接获取 BoundSql 和 MappedStatement
// 在 StatementHandler 流程中,BoundSql 已经被生成
BoundSql boundSql = handler.getBoundSql();
// 通过反射获取委托对象中的 MappedStatement
MappedStatement ms = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 确保获取到信息,避免空指针
if (ms == null) {
return invocation.proceed();
}
// 生成最终SQL(带参数)
String finalSql = "";
String originalSql = "";
String statId = ms.getId();
...
}
}
|
通过这种方式改写后,getBoundSql的性能瓶颈点去掉了。
后记
通过本次优化,请求耗时从到,优化
- 简单性能调优通过代码中打点计算方法调用时间是可以的。如果需要对细粒度的方法调用定位瓶颈点总不能对每个方法调用前后都加打点吧?这里推荐使用阿里开源的Arthas的trace功能。这个可以打印方法调用级别的耗时。

如果调用次数比较多时,为了抓到耗时长的调用。可以把n参数设置大一点;另外也可以加上**’#cost > 10’参数只捕获超过10ms的调用
1
| trace com.xxx.config.mybatis.SqlMonitorInterceptor intercept -n 100 '#cost > 10' --skipJDKMethod false
|
最终优化后通过Arthas trace看到的效果如下
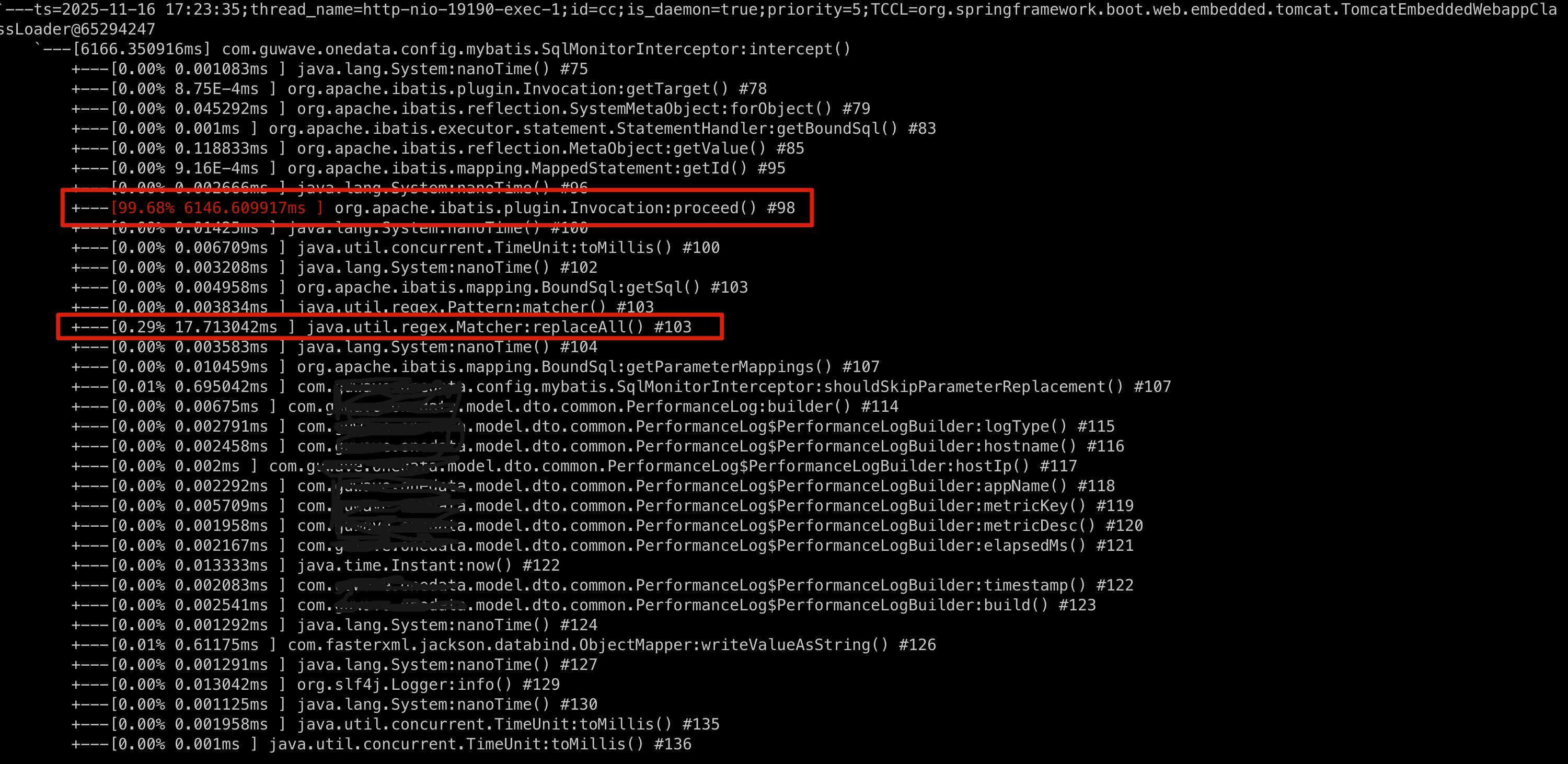
两轮优化后,剩下的瓶颈是空格字符串替换。这个跟我们框架有关,生成的SQL是代码生成的,中间会有比较多的空格换行。上报和人工阅读SQL时不友好,所以做了一次多个空格合并成一个的优化。这个按需开启
简单字符串操作不要用正则表达式,特别是循环中
性能调优跟环境相关,相同请求多次调用后得到耗时指标可能相差很大。原因跟缓存、依赖服务可用性比如Redis等相关
拦截器一定会有性能损耗(10~100毫秒)。线上对时间比较敏感的业务不建议开启SQL监控。这个可以通过系统全局开关来支持